

Category: Data Science
-

2023 UPDATE: California Lottery – Scratchers – picking the winning tickets using math
2023 UPDATE: Full analysis in this spreadsheet has been updated to reflect the latest products offered by California Lottery. I’ve always been fascinated by how the lottery works. From a mathematical point of view spending money on lottery tickets is a complete waste of time and money. There are a few exceptions – when a…
-
Monty Hall Problem – How Randomness Rules Our World and Why We Cannot See It
Ever since I read about Monty Hall problem in “The Drunkard’s Walk: How Randomness Rules Our Lives” book by Leonard Mlodinow from of the California Institute of Technology, I always wanted to try and run a simulation to see that the math is correct. It is one of those problems, where the first answer that comes…
-
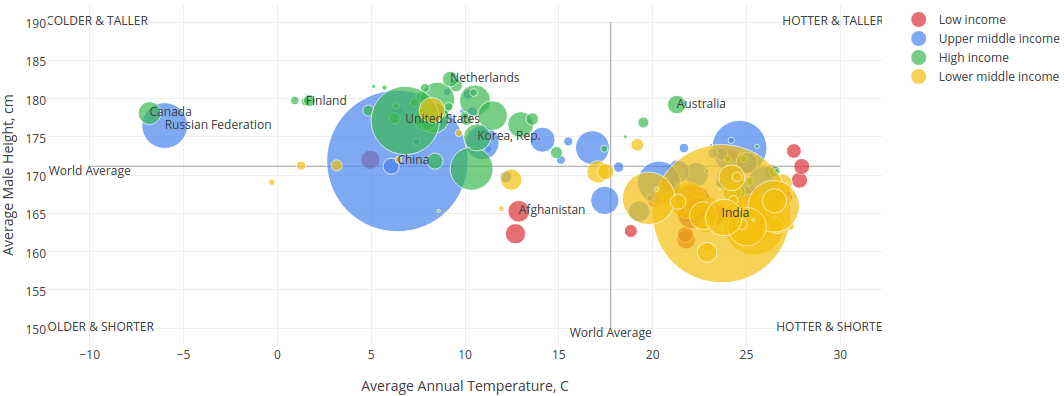
Are People in Colder Countries Taller? in Julia
Continuing to play with Julia and data visualizations. This time I decided to replicate a scatterplot created by Matt Stiles examining the relationship between a country’s average temperature and its male residents’ average height. Data comes from WorldBank and NCD-RisC. The size of the bubbles is linearly proportional to country population. Color indicates new World Bank income categories. People seem to…
-
Life Expectancy by Country
I was inspired by Andrew Collier’s blog post Life Expectancy by Country where he illustrated how to create a bubble chart that compares female and male life expectancies for a number of countries based on the data scraped from Wikipedia using R and Plot.ly charts. I decided to replicate these results using another popular language for technical computing – Julia. Scraping Wikipedia in…
-
Measuring user retention using cohort analysis with R
Cohort analysis is super important if you want to know if your service is in fact a leaky bucket despite nice growth of absolute numbers. There’s a good write up on that subject “Cohorts, Retention, Churn, ARPU” by Matt Johnson. So how to do it using R and how to visualize it. Inspired by examples…
-
Heat map visualization of sick day trends in Finland with R, ggplot2 and Google Correlate
Inspired by Margintale’s post “ggplot2 Time Series Heatmaps” and Google Flu Trends I decided to use a heat map to visualize sick days logged by HeiaHeia.com Finnish users. I got the data from our database, filtering results by country (Finnish users only) in a tab separated form with the first line as the header. Three columns…
-
Informal notes from Strata 2012 conference on Big Data and Data Science
It’s been almost a month since I came back from California, and I just got around to sorting the notes from O’Reilly Strata conference. Spending time in the Valley is always inspiring – lots of interesting people, old friends, new contacts, new start-ups – it is the center of IT universe. Spending 3 days with…


