

Random notes…
Product management · AI · Web3 · Real estate · Angel investments


-

Same as Ever: A Timeless Exploration of Human Behavior by Morgan Housel
In his latest book, Morgan Housel takes us on a journey through the unchanging patterns of human nature, their influence on our decisions, and their echoes through history. Housel begins with a gripping and deeply personal story titled “Hanging by a Thread.” He recounts a past avalanche accident in Squaw Valley – an incredibly relatable…
-

Highlights of the Books I Read in 2023: A Journey Through Ideas, Insights, and Adventures
The year 2023 offered an eclectic mix of literary landscapes, and I had the pleasure of traversing some truly remarkable ones. Here’s a peek into the books that sparked curiosity, broadened perspectives, and left me with lingering thoughts: Delving into the Minds of Machines and Man: Navigating the Turbulent Tides of History: Silicon Valley and…
-

2023 UPDATE: California Lottery – Scratchers – picking the winning tickets using math
2023 UPDATE: Full analysis in this spreadsheet has been updated to reflect the latest products offered by California Lottery. I’ve always been fascinated by how the lottery works. From a mathematical point of view spending money on lottery tickets is a complete waste of time and money. There are a few exceptions – when a…
-

Life 3.0: Being Human in the Age of Artificial Intelligence by Max Tegmark
The saddest aspect of life right now is that science gathers knowledge faster than society gathers wisdom. – Isaac Asimov Just finished reading Life 3.0 and I can say it does deserve being put on a mandatory reading list for anyone working in AI field. This is not a popular science book, but a great…
-

One of the strangest books I read lately: “Russia Rising” by Seth Chanowitz
“Russia Rising” by Seth Chanowitz is probably one of the strangest books I read in the past few years. I don’t even remember how I came across it – must’ve been the magic of Amazon’s recommendation algorithms. It caught my eye as the description said that “It takes places in Finland, Estonia, Russia, Belarus, and…
-
Monty Hall Problem – How Randomness Rules Our World and Why We Cannot See It
Ever since I read about Monty Hall problem in “The Drunkard’s Walk: How Randomness Rules Our Lives” book by Leonard Mlodinow from of the California Institute of Technology, I always wanted to try and run a simulation to see that the math is correct. It is one of those problems, where the first answer that comes…
-
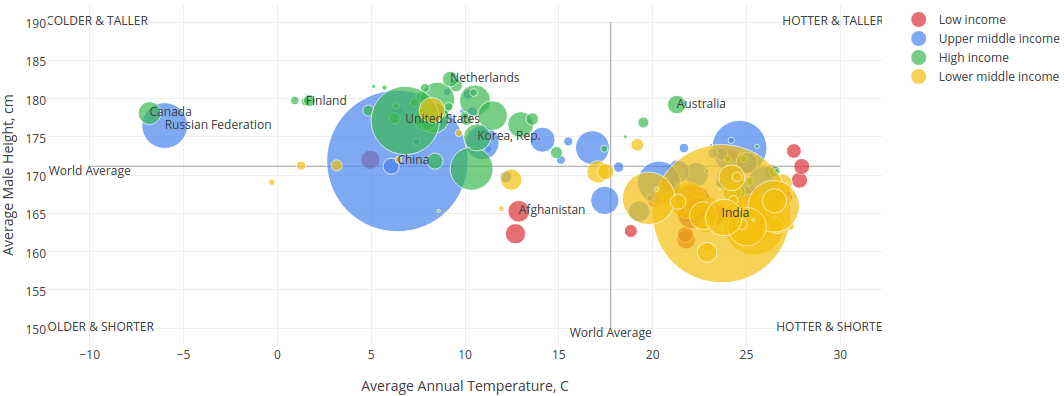
Are People in Colder Countries Taller? in Julia
Continuing to play with Julia and data visualizations. This time I decided to replicate a scatterplot created by Matt Stiles examining the relationship between a country’s average temperature and its male residents’ average height. Data comes from WorldBank and NCD-RisC. The size of the bubbles is linearly proportional to country population. Color indicates new World Bank income categories. People seem to…
-
Life Expectancy by Country
I was inspired by Andrew Collier’s blog post Life Expectancy by Country where he illustrated how to create a bubble chart that compares female and male life expectancies for a number of countries based on the data scraped from Wikipedia using R and Plot.ly charts. I decided to replicate these results using another popular language for technical computing – Julia. Scraping Wikipedia in…
-

“The Nordic Theory of Everything: In Search of a Better Life” by Anu Partanen
Anu Partanen is a Finnish journalist now living and working in the United States. In her new book “The Nordic Theory of Everything. In Search of a Better Life” she compares how Nordic/Finnish and American societies address key issues such as healthcare, education, parental leaves, unemployment. This books hits close to home. I’m a naturalized Finnish…
-
“High Performance MySQL” by Baron Schwartz, Peter Zaitsev, and Vadim Tkachenko; O’Reilly Media
Peter and Vadim are long-term contributors to MySQL open source code base and are the founders of Percona, MySQL consultancy. This is really THE book about MySQL written by engineers who have spent more than a decade working on MySQL code. The book is equally valuable to devops and DB admins, as well as software…







